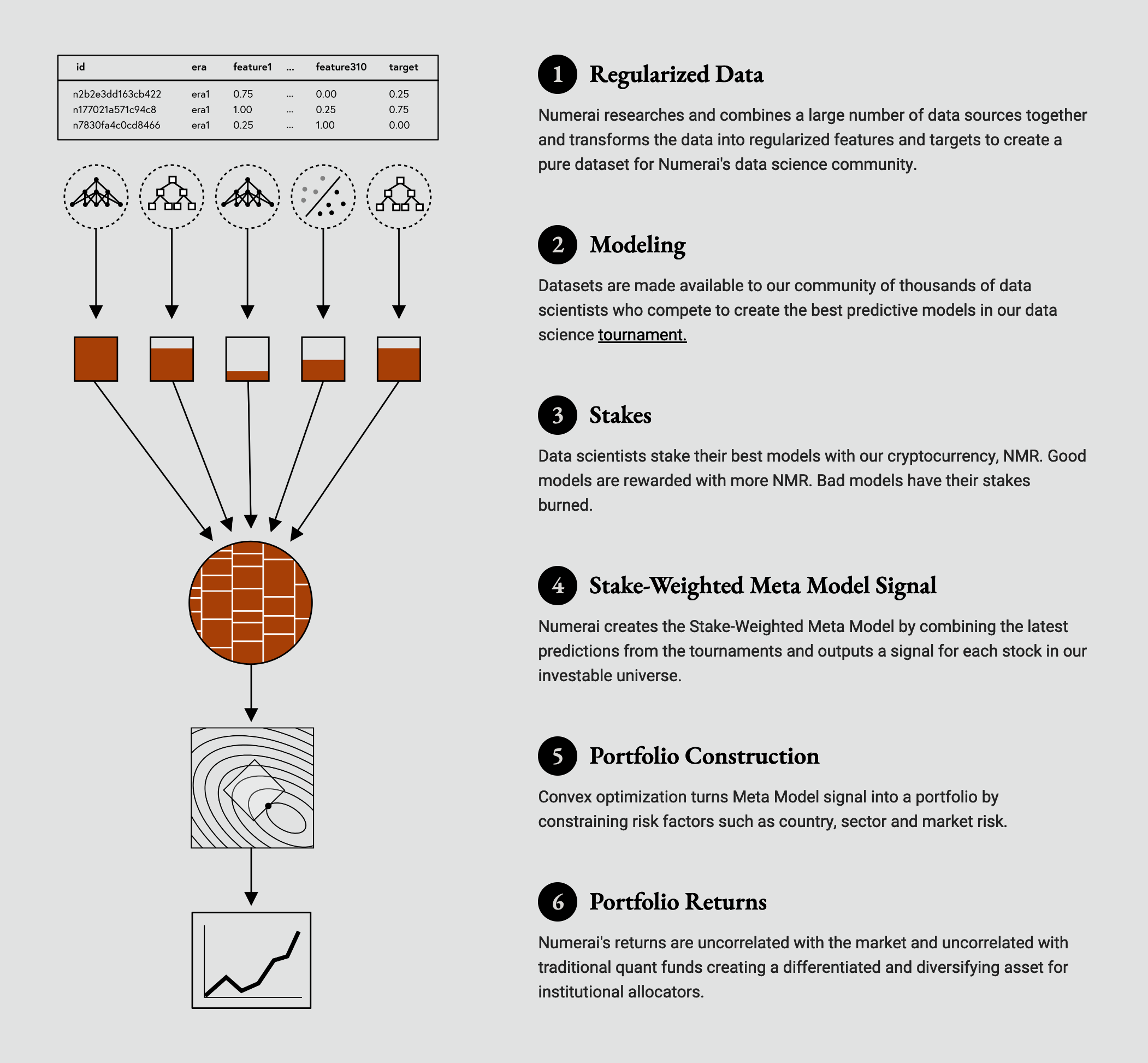
Hedgefund overview, taken from numer.ai.
Approaches
I first split the training data into 4 parts, creating 4 different subsets, each containing 3 parts as training and the remaining part as validation. There are 20 different targets provided for the tournament, so I trained 80 small models, one for each combination of target and subset. The predictions of these models were then averaged based on their performance on the respective validation set of their subset. I tried random forests as well as neural networks, the former performed better. Both had high correlation with the targets, but were highly dependent on single features (high feature exposure).This still worked well when the tournament was based on pure correlation with the targets, but when it switched to a scoring function based on true contribution to the meta model, I had to come up with a new approach. When the scoring function changed, they also started to release the newest data every week. My new approach was to train a huge random forest model on all the data and then overfit it to the current regime by retraining it on the newest data every week. The optimal parameters for retraining learning rate, number of additinoal trees and how recent the data had to be to be included in the retraining were found by grid search. This required a lot of computing power, so I started using AWS Sagemaker, but realized that it would be to costly to use it for all my experiments, so I started looking for second hand hardware and started my computation cluster project. Although some parameters worked well in validation, so I used the cluster to submit the results automatically every week, to find out how they would fare in the true contribution scoring. They did not perform well, so I tried a simpler approach, training the random forest model on the whole data including the newest epochs every week. This works well and is still my current approach.
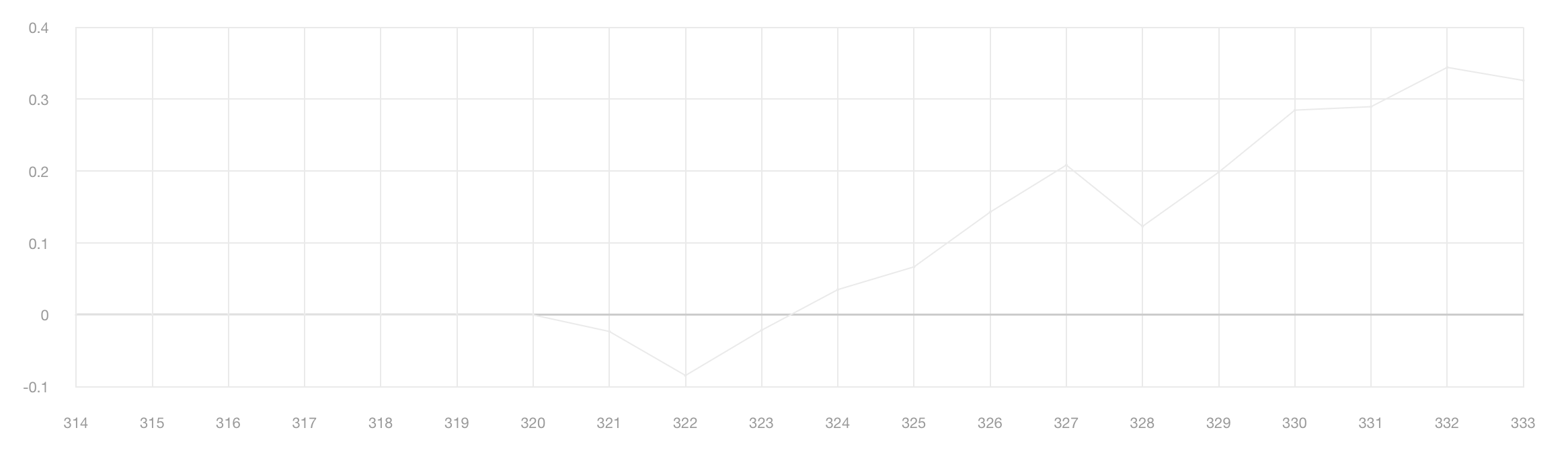
Cumulated True Contribution scores per epoch.